Изучение требований к операциям ввода-вывода (I/O) с
файлами баз данных Microsoft SQL Server поможет Вам поднять
производительность системы и избежать ошибок, связанных с
I/O.
Поскольку на рынке продолжают появляться новые устройства и
решения для дисковых хранилищ, условия, в которых работает
Microsoft SQL Server, стали чрезвычайно разнообразным. Чтобы
гарантировать целостность данных, которые обслуживает SQL
Server, очень важно, что бы подсистема I/O обладала
соответствующими функциональными возможностями. Цель этой
статьи состоит в том, чтобы описать требования к I/O для
операций с файлами баз данных SQL Server, на основании чего
поставщики решений и пользователи могли бы проанализировать и
оптимизировать свои системы с SQL Server.
Важно: При планировании, развертывании и поддержке
Microsoft SQL Server, убедитесь, что система ввода-вывода
удовлетворяет всем факторам, на которые акцентируется внимание
в этой статье.
Microsoft Knowledge Base и Microsoft SQL Server Books
Online (BOL) содержат много подробной информации, связанной с
операциями I/O в SQL Server. В тексте, при необходимости,
автором указываются ссылки на информацию, которая важна для
понимания предлагаемого в этой статье материала. Важно:
Автор рекомендует полностью ознакомиться с материалом, на
который он ссылается, перед тем, как Вы начнёте изучать
следующие за ссылкой главы. Справочная система Books Online
(BOL): Все ссылки на BOL, используемые в этой статье, взяты из
Microsoft SQL Server 2000 Books Online (обновлённая редакция,
с учётом новшеств SP3), который можно скачать по этой ссылке:
.
Если в открывшейся странице нажать на ссылку Product
Documentation, можно выбрать альтернативный вариант просмотра
BOL в интерактивном режиме.
В этой главе представлены наиболее распространённые
термины, которые используются в этой статье и в других
документах, ссылки на которые автор использует по ходу
изложения материала.
Требования
ACID
Это аббревиатура от Atomicity, Consistency, Isolation и
Durability, которая применяется для описания основных
требований к SQL Server по организации транзакций,
предъявляемых к надежным серверам баз
данных. Атомарность: Atomicity - транзакция должна
быть атомарной для исполняемого блока команд. Или все её
изменения данных будут исполнены, или не будет исполнено ни
одно из них. Последовательность: Consistency - после
завершения транзакции данные должны оставаться в
непротиворечивом состоянии. В реляционной базе данных, должны
быть предприняты все меры к тому, чтобы поддерживать
целостность данных во время исполнения модифицирующих данные
транзакций. Все внутренние структуры данных, например:
бинарные деревья индексов или дважды связанные списки, не
должны нарушаться после завершения
транзакции. Изоляция: Isolation - изменения,
сделанные в параллельных транзакциях, должны быть изолированы
от изменений, сделанных другими исполняемыми параллельно
транзакциями. Транзакция должна видеть данные в том состоянии,
какими они были до изменения их другой параллельной
транзакцией, или в том состоянии, в каком данные окажутся
после завершения второй транзакции, но не должна видеть их
промежуточное состояние. Всё это называется сериализацией,
потому что предоставляет системе возможность перезагружать
изначальные данные и повторять серию транзакций, чтобы в
результате данные оказались в том состоянии, в каком они
должны быть после исполнения первичной
транзакции. Неизменность: Durability - после того,
как транзакция завершена, результаты её работы в системе не
должны изменяться. Изменения должны сохраняться даже в случае
отказа системы.
Write-Ahead Logging - Упреждающее журналирование является
ключевым методом обеспечения требований ACID. WAL позволяет
обеспечить сброс на диск записей из журнала транзакций,
относящихся к изменениям данных, раньше того, как будут
сброшены на диск сами эти изменённые страницы данных. Ниже, в
этой статье, механика WAL будет описана более подробно.
Долговременные носители часто путают с физической памятью.
SQL Server использует долговременные носители в качестве
памяти, которая может пережить рестарт системы или её отказ.
Долговременными носителями обычно считают память физического
диска, однако к ним относятся и другие устройства, а также
некоторые средства кэширования. Многие высокопроизводительные
дисковые подсистемы имеют высокоскоростные средства
кэширования, позволяющие уменьшить время ожидания для операций
чтения и записи. Этот кэш часто резервируется и обладает
автономным питанием от собственной батареи. Автономная батарея
обеспечивает питание и соответственно сохранность данных в
кэше до нескольких дней, но реализация такого резервирования
отличается у разных производителей. Производители могут
поставлять батареи опционально, чтобы увеличить жизнь кэша,
если это необходимо заказчику. Идея такого решения состоит
в том, что бы после того, как проблема с системой будет
устранена, сохранённые в кэше записи отработались бы так, как
будто никогда не было отказа или рестарта. Реализация такого
решения у большинства производителей подразумевает немедленный
сброс на диск содержимого кэша, в то время, пока система будет
перезапускаться. Ниже представлены примеры ситуаций
успешного разрешения описанных выше проблем, с которыми
реально сталкивается персонал Microsoft SQL Server Product
Support Services.
Пример 1: Аппаратный отказ (материнская плата) У
контроллера была встроенная батарея для защиты кэша данных.
Был проинсталлирован новый компьютер, и к нему были подключены
контроллер с подсистемой I/O. Во время старта, контроллер
сбросил на диск всё содержимое кэша, после чего команда DBCC
показала отсутствие проблем с целостностью данных.
Пример 2: Отказ электропитания Батарейка на
контроллере позволила сохранить данные кэша в течение четырех
дней (с заменой батареек), пока электропитание не было
восстановлено к норме. Во время старта, контроллер сбросил на
диск всё содержимое кэша, после чего команда DBCC показала
отсутствие проблем с целостностью данных.
Важно: Необходимо всегда консультироваться с
поставщиком/изготовителем аппаратных средств для того, что бы
выбрать правильную стратегию использования долговременных
носителей.
Если происходит сбой аппаратных средства или питания, после
восстановления Microsoft рекомендует обязательно выполнить
полную проверку данных командой DBCC CHECKDB и всегда иметь
полный набор резервных копий, что позволит гарантировать
целостность данных.
Порядок записи или последовательность записи (write
ordering / write dependency) - это сохранение подсистемой I/O
порядка операций ввода-вывода. Как было сказано ранее,
долговременные носители могут использовать кэширование. Если
отследить метки времени, долговременные носители должны
обеспечить порядок их сохранения для операций I/O. Порядок
операций I/O, связанных с SQL Server, должен строго
соблюдаться. Система должна обеспечить соответствующее
упорядочение записи, иначе она нарушит протокол WAL, который
подробно будет описан ниже (записи в журнале должны
сохраняться в правильном порядке, и они всегда должны
сохранятся на устройстве долговременного носителя до
сохранения страниц данных, которые соответствуют эти записям в
журнале). После того, как записи из transaction log будут
успешно сброшены на диск, связанные с ними страницы данных
тоже могут быть туда записаны. Если подсистема ввода-вывода
разместит страницы данных на долговременном носителей раньше,
чем записи журнала, целостность данных может быть
нарушена. Например, если компьютер, на котором работает SQL
Server, будет перезагружен после того, как страницы данных
сохранятся на долговременном носителе, но до того, как туда
попадут соответствующие им записи журнала, во время следующего
запуска процесса реорганизации (recovery) для базы данных -
могут возникнуть ошибки. Поскольку в журнале не будут
обнаружены записи об изменении страниц, процесс recovery не
сможет определить для этих страниц реальное состояние
транзакций. Поскольку записи журнала не сохранена на диск
долговременного носителя, процесс recovery не сможет
определить, что эти страницы должны быть откачены к
предыдущему состоянию, и не будет пытаться исправить эту
проблему, оставляя, таким образом, базу данных в
несогласованном состоянии.
Многие высокопроизводительные дисковые подсистемы
балансируют нагрузку по нескольким, имеющимся каналам передачи
запросов I/O. Эти системы должны обеспечивать порядок
следования запросов I/O. Многие из таких систем поддерживают
порядок I/O за счёт использования кэша долговременного
носителя и последующего комбинирования и/или разбиения
запросов на I/O между доступными ресурсами подсистемы, чтобы
потом сохранить их на физических носителях. Для получения
дополнительной информации о балансировании I/O ознакомьтесь с
этой статьёй:
Прерванный I/O (Torn I/O) в документации SQL Server часто
упоминается ещё как оборванные страницы (torn page).
Прерванный I/O происходит при частичной записи, после чего
данные остаются в несогласованном состоянии. В SQL Server
2000/7.0 страницы данных имеют размер 8 Кбайт. Разрыв страниц
данных в SQL Server происходит тогда, когда только часть из 8
Кбайт будет правильно записана или прочитана с долговременного
носителя. SQL Server всегда проверяет состояние данных
после завершения I/O, что бы идентифицировать любые ошибки
операционной системы, и соответствие размера передаваемых
данных, а затем обрабатывает возможные ошибки. Оборванные
страницы могут появиться после отказа системы, в случае если
подсистема ввода - вывода при запросе I/O не завершит
полностью запись/чтение 8 Кбайт данных. Производители
дисков ограничивают передачу данных размером сектора диска,
равным 512 байт, поэтому, если долговременным носителем
является физический диск, и его контроллер не имеет кэша с
автономной батареей, запрос I/O в итоге ограничивается
скоростью вращения шпинделя диска. Таким образом, если I/O
пытается записать 8 Кбайт (имея шестнадцать 512-байтных
секторов), но успешно на долговременный носитель запишутся
только первые три сектора, в этом случае страница становится
оборванной, что приведёт к нарушению целостности данных, т.к.
последующее чтение страницы размером в 8 Кбайт получило бы 3
сектора новой версии страницы данных и 13 секторов старой
версии. SQL Server умеет обнаруживать оборванные страницы,
анализируя базу данных. Часть первого 512-байтного сектора
страницы содержит заголовок, в котором содержится информация
каждом из 512-байтных секторов являющимися частями 8-ми
Кбайтной страницы. Обнаружить обрыв страницы можно анализируя
заголовок оборванной страницы. Обнаружение оборванных
страниц требует минимальных ресурсных затрат и является
рекомендуемой практикой администрирования SQL Server. Чтобы
прочитать больше об обнаружении оборванных страниц, см. статью
"Torn Page Detection" в SQL Server Books Online.
Изготовители аппаратных средств гарантируют, что сектор
записывается полностью, поэтому файлы журнала транзакций SQL
Server 2000 всегда записываются кусками, равными размеру
сектора. Каждый сектор журнала транзакций содержит флаг
четности. Этот флаг используется, что бы убедиться в
правильности записи последнего сектора. Во время процесса
recovery, в журнале анализируется его последний, записанный
сектор. Таким образом, записи журнал транзакций могут
использоваться для возвращения базы данных в соответствующее
транзакционное состояние.
Зеркальное
отражение и удалённое зеркальное отражение
дисков
Зеркальное отражение - это распространённая практика
обеспечения избыточности данных и очень важный инструмент
защиты данных. Зеркальное отражение можно реализовать на
программном или аппаратном уровне. Наиболее
распространённой является аппаратное решение, зеркально
отражающие образы дисков на физическом уровне. Развитие этой
технологии привело к возможности отражения на диски,
находящиеся друг от друга на большом расстоянии. Сегодня на
рынке доступны несколько типов реализаций зеркального
отражения. Некоторые из них базируются на использовании кэша,
другие направляют I/O на все зеркальные тома данных и
контролируют, что бы запросы I/O были выполнены полностью на
всех томах. В любом случае, все эти реализации должны
соблюдать порядок записи. SQL Server считает зеркало
долговременным носителем, копирование данных на который
осуществляется по меткам времени, что является одним из
ключевых моментов этой технологии. На отраженной подсистеме
должен строго соблюдаться протокол WAL, без чего невозможно
будет обеспечить исполнение требований ACID. Отраженная
подсистема должна в точности повторять все метки времени, как
они были в первичных данных. Например, многие
высокопроизводительные дисковые подсистемы могут обслуживать
несколько каналов I/O. Если журналы базы данных помещены на
одно зеркало, а файлы данных на другое, поддержка порядка
записи уже не может быть обеспечена только одним аппаратным
компонентом. Без дополнительных механизмов, порядок записи
страниц данных и журнала транзакций на зеркальные диски не
может быть реализован таким образом, что бы соблюсти порядок
меток времени. Эти дополнительные механизмы отражения
необходимы, чтобы гарантировать порядок записи на несколько
физических, зеркальных устройств. Иногда, их называют
зеркальными группами (Mirror Groups) или последовательными
группами (Consistency Groups). Для получения дополнительной
информации, прочтите эту статью:
Forced Unit Access - сквозной доступ (FUA) происходит
тогда, когда файл открыт (используется CreateFile) с флагом
FILE_FLAG_WRITETHROUGH. SQL Server открывает все базы данных и
журналы с этим флагом. Флаг указывает на то, что любой
запрос на запись с битом FUA нужно посылать непосредственно
подсистеме I/O. Этот бит указывает подсистеме, что данные
должны попасть на долговременный носитель до того, как I/O
будет считаться законченным, т.е. операционная система выдаст
сообщение о завершении I/O. При этом не должен использоваться
промежуточный кэш, который не относиться к долговременному
носителю. Другими словами, запись должна идти непосредственно
в долговременный носитель, и такой процесс принято называть
сквозной записью (writethrough). Такой доступ позволяет
предотвратить проблемы, которые могут возникнуть, когда кэш
(например, кэш операционной системы, который не является
автономным, как кэш с батарейкой), принимает I/O и сообщает
SQL Server, что I/O завершен успешно, а фактически данные ещё
не были сохранены на долговременном носителе. Без такого
доступа, SQL Server не смог бы полагаться на систему для
обеспечения протокола WAL. Стоит поинтересоваться у
изготовителя по поводу поддержки FUA его оборудованием.
Некоторые аппаратные средства обрабатывают состояние FUA как
индикатор того, что данные должны быть сохранены на физическом
диске (даже если он оборудован автономным кэшем с батарейкой).
Другие устройства полагаются на то, что кэш с батарейкой можно
считать долговременным носителями, который поддерживает FUA.
Разница в таких подходах может сильно влиять на
производительность SQL Server. Подсистема, которая
поддерживает кэширование долговременного носителя, как
правило, намного быстрее осуществляет запись, чем подсистема,
которая требует, чтобы данные были записаны на физический
носитель. Важно: Спецификации и реализации IDE дисков не
имеют ясных стандартов того, как они обслуживают FUA запросы.
Спецификации SCSI дисков и их реализации предусматривают
использование FUA запросов, отключают кэши физической дисковой
системы и другие механизмы кэширования. У многих IDE систем,
запрос FUA просто будет отвергнут аппаратными средствами IDE
дисков, делая, таким образом, этот тип дисковых подсистем
опасным для работы SQL Server или других программ, которые
полагаются на поддержку FUA. Из-за необходимости обеспечения
реакции на установку FUA, некоторый производители IDE дисков
создают утилиты, которые блокируют кэш IDE диска, что
позволяет обезопасить работу SQL Server. Важно: Некоторые
версии Microsoft Windows не всегда передают бит FUA аппаратным
средствам. Соответствующие исправления были внесены, начиная с
Windows 2000 Service Pack 3 (SP3), после которого бит FUA
теперь всегда обрабатывается правильно. Для обратной
совместимости, Microsoft выпустил утилиту Dskcache.exe,
которая позволяет управлять этим поведением операционной
системы. Используйте эту утилиту, чтобы управлять реакцией
на флаг FUA, если компьютер обслуживает SQL Server, а диски
имеют кэш. Утилита может быть получена у Microsoft, для
получения более подробной информации, изучите статью:
Примечание переводчика: В Windows 2000 Advanced Server
службы Active Directory при запуске отключают кэширование
записи для жестких дисков.
Размер страницы базы данных SQL Server равен 8 Кбайт.
Каждая страница содержит заголовок с полями номера страницы,
идентификатора объекта, LSN, идентификатора индекса, бита
чётности (Torn bits) и типа страницы. Сами строки данных
расположены на оставшейся части страницы. Внутренние механизмы
базы данных отслеживают состояние распределения страниц данных
в базе. Страницы данных часто просто называют
страницами.
Номера страниц могут принимать значения от 0 до
((Максимальный размер файла / 8 Кб)-1). Номер страницы,
умноженный на 8 Кбайт, даёт смещение в файле к первому байту
страницы. Когда страница считывается с диска, номер
страницы сразу же проверяется, чтобы определить правильность
заданного смещения (номер страницы в заголовке по сравнению с
ожидаемым номером страницы). Если номер не совпадает, SQL
Server генерирует ошибку 823.
Это идентификатор объекта, который назначен странице в
схеме базы данных. Страница может быть назначена только на
единственный объект. Когда страница читается с диска, у
страницы проверяется ID объекта. Если ID объекта не
соответствует ожидаемому, SQL Server генерирует ошибку
605. SQL Server часто осуществляет запись кратно размеру
страницы, 8 Кбайт или больше.
Обычно SQL Server (если исключить не смешанные экстенты)
распределяет место не только страницами, но и экстентами.
Экстент - это блок из восьми страниц по 8 Кб, всего 64 Кб. SQL
Server часто читает сразу экстентами (64 Кб или 128 Кб).
Буферный пул - Buffer Pool (BPool) занимает наибольшую
часть адресного пространства непривилегированного режима,
оставляя только около 100 Мбайт для диапазона виртуальных
адресов, используемых для стеков потока, библиотек DLL и др.
Буферный пул резервируется большими кусками, но кратными
рабочему размеру страницы базы данных - 8 Кб.
Аппаратный кэш чтения - это обычный кэш упреждающего
чтения, используемый контроллерами. В зависимости от размера
доступного кэша, кэш упреждающего чтения используется для
повышения производительности извлечения данных, которых
помещается в кэш больше, чем фактически запрашивается для
чтения. Аппаратный кэш чтения и упреждающее чтение бывает
более выигрышен для приложений, данные которых обычно имеют
непрерывный характер и читаются практически непрерывными
кусками, например, это могут быть OLAP запросы или приложения
отчётности. Поскольку аппаратный кэш чтения утилизирует
часть памяти кэша, которая могла бы использоваться для
буферизации запросов на запись, его использование может мешать
оперативным транзакциям (OLTP), для которых требуется высокая
скорость записи. Важно: Некоторые контроллеры не выполняют
упреждающее чтение, если размер запроса на чтение превышает 16
Кб. В таком случае, для серверов с Microsoft SQL Server,
аппаратное упреждающее чтение не даёт заметных преимуществ,
потому что запросы I/O на чтение, как правило, больше 16
Кбайт. Изучите документацию или свяжитесь с производителем
Вашей дисковой подсистемы, что бы получить рекомендации по
настройке аппаратной части для поддержки работы SQL
Server.
Аппаратный кэш записи обслуживает не только запросы на
запись, но и запросы на чтение, если данные все еще находятся
в аппаратном кэше записи. Это распространённый механизм
кэширования I/O. Возможность аппаратного кэширования записи
является очень важной в поддержании высокой производительности
OLTP систем. С поддержкой автономного питания от встроенной
батареи и соответствующих, безопасных алгоритмов работы,
аппаратный кэш записи может обеспечить безопасность данных (на
долговременных носителях), а так же повысить быстродействие
подобных SQL Server приложений, реально сокращая расходы на
физические операции ввода-вывода.
SQL Server error 832, "I/O error <error> detected
during <operation> at offset <offset> in file
'<file>'"
Происходит когда:
операции ReadFile, WriteFile, ReadFileScatter,
WriteFileGather или GetOverlappedResult приводят к одной из
ошибок операционной системы.
номер страницы при чтении страницы с диска не совпадает с
ожидаемым ID страницы.
не правильный размер передаваемых данных.
обнаружено прерванное чтение, когда включено определение
оборванных страниц.
обнаружено чтение устаревших данных (Stale Read), когда
включено определение такого чтения.
Примечание переводчика: Stale Read возникает при
запросах ReadFile API, если операционная система, драйвер или
кэширующий контроллер ошибочно возвращает старую версию
кешируемых данных.
SQL Server error 605, "Attempt to fetch logical page
(x:yyy) in database 'dddd' belongs to object 'aaa', not to
object 'tttt'."
Происходит когда:
ID объекта на странице не соответствует ID объекта,
который ожидалось прочитать в заголовке
страницы.
Ошибка 605 у SQL Server проявляется, когда к странице
обращаются для сканирования. Сканирование ассоциируется с
конкретным объектом. Если при сканировании ID не соответствует
ID объекта, который хранится в заголовке страницы,
генерируется эта ошибка. Это происходит в момент первого
использования страницы и может произойти при последующем
поиске страницы в оперативной памяти.
Для полного понимания дизайна ввода - вывода в SQL Server
важно знать основные принципы операций I/O с файлами баз
данных, журналами транзакций и последовательность обслуживания
транзакций. Дизайн I/O и транзакций в SQL Server
гарантируют, что правила ACID будут полностью выполнены. Эта
глава посвящена свойству "Неизменности" результатов исполнения
транзакций и его поддержке средствами операционной системы и
аппаратными средами.
Ключевым элементом обеспечения правил ACID является
протокол WAL. Протокол WAL требует, чтобы все записи журнала
транзакций, связанные с относящимися к ним страницами данных,
были сброшены на диск долговременного носителя до того, как
сами страницы данных будут сброшены на диск. Microsoft SQL
Server 2000 и Microsoft SQL Server 7.0 используют страницы
данных размером 8 Кб и кратный размеру сектора диска размер
буфера журнала транзакций. Более ранние версии SQL Server
использовали страницы данных и журнала транзакций размером в 2
Кб. Давайте рассмотрим пример кода, приведённый в статье
Microsoft Knowledge Base:
Рассмотрим на примере, как SQL Server поддерживает протокол
WAL для инструкции INSERT. В этом примере предполагается, что
индексы не используются и страница, которая будет
задействована, имеет номер 150.
BEGIN TRANSACTION
INSERT INTO tblTest VALUES (1)
COMMIT TRANSACTION
Инструкция
Выполняемое действие
BEGIN TRANSACTION
Запись в журнале транзакций, относящаяся к BeginTran,
помещается в кэш журнала, но пока нет надобности
сбрасывать её на диск долговременного носителя, потому
что SQL Server ещё не сделал никаких физических
изменений.
INSERT INTO tblTest
1. Страница 150 не присутствует в этот момент в кэше
SQL Server, поэтому страница данных с номером150
помещается в кэш данных SQL Server. 2. Выставляются
соответствующие блокировки и страница подвергается
краткой блокировке (latch). 3. Формируется запись в
журнале транзакции о вставке значения в таблицу и эта
запись попадает в кэш журнала. 4. Новая строка
добавляется на страницу данных, и эта страница
помечается, как "грязная" (dirty). 5. Снимается
краткая блокировка. 6. Записи журнала, связанные с
транзакцией, в этот момент не должны ещё быть сброшены
на диск, потому что все изменения находятся в
автономной, энергозависимой памяти.
COMMIT TRANSACTION
7. Генерируется запись о завершении транзакции.
Записи в журнале, связанные с транзакцией (и все
предыдущие записи журнала) должны быть сохранены на
долговременном носителе. Транзакция не будет считаться
завершённой, пока записи из журнала не будут без ошибок
сброшены на диск долговременного носителя (журнал
фиксируется). 8. Страница данных с номером 150
остается в кэше данных SQL Server и не будет немедленно
сброшена на диск долговременного носителя. В сбрасывании
её на диск нет необходимо, потому что после того, как
записи журнала транзакций были успешно защищены,
становиться возможным исполнение операции реорганизации
(recovery), чтобы откатить назад транзакцию, на
основании записей в журнале транзакций. 9. Снимается
транзакционная блокировка, и блок кода считается
исполненным.
Блокировка и краткая блокировка являются обособленными
вопросами при поддержке протокола WAL. Блокировка поддерживает
целостность данных в транзакциях, в то время как краткая
блокировка поддерживает физическую целостность данных. В
предыдущем примере, SQL Server 7.0 и SQL Server 2000
используют краткую блокировку страницы 150 только в течение
того времени, которое необходимо для физических изменений на
странице, а не на всё время исполнения транзакции.
Соответствующий тип блокировки устанавливается по мере
необходимости для защиты строки, блока строк, страницы или
таблицы целиком. Для подробного ознакомления с разными
типами блокировок, посмотрите посвящённые им главы Microsoft
SQL Server Books Online. Рассматривая предыдущий пример
работы протокола WAL более подробно, может возникнуть вопрос,
что случается если процесс отложенной записи или процесс
контрольной точки отработает раньше, чем будет иметь место
COMMIT, но уже после изменения страницы данных? Давайте снова
вернёмся к используемому нами примеру и рассмотрим поведение
протокола WAL в этом случае:
Инструкция
Выполняемое действие
BEGIN TRANSACTION
Запись в журнале транзакций, относящаяся к BeginTran,
помещается в кэш журнала, но пока нет надобности
сбрасывать её на диск долговременного носителя, потому
что SQL Server ещё не сделал никаких физических
изменений.
INSERT INTO tblTest
1. Страница 150 не присутствует в этот момент в кэше
SQL Server, поэтому страница данных с номером150
помещается в кэш данных SQL Server. 2. Выставляются
соответствующие блокировки и страница подвергается
краткой блокировке (latch). 3. Формируется запись в
журнале транзакции о вставке значения в таблицу и эта
запись попадает в кэш журнала. 4. Новая строка
добавляется на страницу данных, и эта страница
помечается, как "грязная" (dirty). 5. Снимается
краткая блокировка. 6. Записи журнала, связанные с
транзакцией, в этот момент не должны ещё быть сброшены
на диск, потому что все изменения находятся в
автономной, энергозависимой памяти.
Процесс отложенной записи или контрольной точки
фиксирует нахождение страницы 150 в буферном пуле
В этот момент страница 150 помечена, как "грязная",
так что оба указанных процесса знают, что страница базы
данных должна быть сброшена на диск долговременного
носителя.
На страницу 150 накладывается краткая блокировка,
чтобы предотвратить её дальнейшие изменения.
Порождается запрос к менеджеру журнала для сброса
на диск всех записей журнала транзакций, включая
имеющее такое значение LSN, которое записано в
заголовке страницы 150. (Журнал транзакций
фиксируется).
Ожидание того, пока все записи журнала регистрации
транзакций не будут успешно сброшены на диск
долговременного носителя.
Порождается запрос I/O на сброс страницы 150 в
долговременный носитель.
Обратите внимание на то, что в последнем примере не
исполняется команда COMMIT. Если страница помечена, как
"грязная", записи журнала могут быть сброшены на диск, а за
ними и соответствующая страница данных, как это положено по
протоколу WAL. Блокировки защищают завершение транзакции и,
если произойдёт откат операции, процесс recovery компенсирует
эти действия, восстановив страницу в надлежащее состояние.
Если бы всё это не работало описанным выше способом, SQL
Server не смог бы выполнить больше изменений, чем позволила бы
разместить его физическая память. Отложенная записи и
контрольная точка разрешают подобные проблемы путём сброса на
долговременный носитель всех записей журнала транзакций,
связанных с "грязной" страницей. Это позволяет поддержать
требования протокола WAL, согласно которым страница данных
никогда не может быть сохранена на долговременном носителе до
связанных с ней записей журнала транзакций. Почитать про
журнал транзакций и об упреждающей записи можно в главе:
"Write-Ahead Transaction Log" из SQL Server Books
Online. Дополнительную информацию можно найти сайте
Microsoft в документе:
Значение порядкового номера журнала (LSN) состоит из трех
частей и представляет собой уникальное инкрементальное
возрастающее значение. Оно используется для организации
последовательности записей журнала транзакций базы данных. Это
позволяет SQL Server соблюдать правила ACID и правильно
выполнять операцию recovery. При изменениях в данных, в
журнале транзакций создаются новые значения LSN. То же самое
значение LSN сохраняется (заменяя предыдущее значение) в
заголовке страницы данных, в котором храниться номер последней
записи в журнале транзакций, и этим самым страница данных
получает соответствие записи в журнале. Чтобы узнать больше
об архитектуре журнала транзакций, смотрите статью
"Transaction Log Logical Architecture" в SQL Server Books
Online.
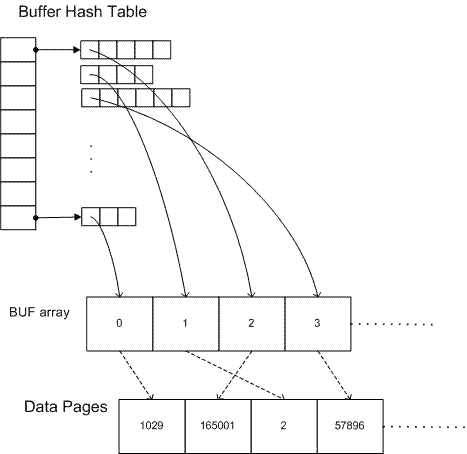
SQL Server использует краткие блокировки во время
синхронизации данных. Блокировки такого типа создаются SQL
Server в непривилегированном режиме, для выполнения операций
записи или чтения. Каждая, находящаяся в памяти страница
данных имеет идентифицирующую буфер структуру (BUF). Массив
BUF структур содержит информацию о состоянии (Dirty, On LRU,
In I/O), и так же о кратких блокировках. Блокировка решает
соответствующие задачи блокирования, а краткая блокировка
контролирует физический доступ. Например, блокировка может
налагаться на страницу, которая не находится в памяти. Краткая
же блокировка возможна только тогда, когда страница данных
находится в памяти. На представленной ниже иллюстрации
показано представление верхнего уровня буферного пула SQL
Server 2000.
Начиная с Microsoft SQL Server 7.0, используются Microsoft
Win32 APIs: WriteFileGather и ReadFileScatter. Функция
WriteFileGather собирает данные от множества разрозненных
частей буфера и записывает эти данные в файл. Функция
ReadFileScatter считывает данные из файла и распределяет их по
нескольким рассредоточенным частям буфера. Эти API не
позволяют SQL Server множить запросы на физический I/O.
Например, во время работы процесса контрольной точки с
шестнадцатью страницами по 8 Кбайт, в итоге, всё может быть
сброшено на диск за один вызов WriteFileGather. Перед
использованием WriteFileGather, SQL Server должен был бы
создавать запрос на I/O для каждой страницы данных, которые
потом должны были быть отсортированы и буферизованы
непосредственно в виде всего большого запроса. Важно:
Сборка и распределение зависят от специфики аппаратных
возможностей. Если аппаратные средства их не поддерживают,
возможности по сборке и распределению перекладываются на
операционную систему, которая должна будет выделять запросы на
I/O. Чтобы Microsoft SQL Server производительно работал с I/O,
убедитесь, что ваша подсистема ввода - вывода изначально
поддерживает операции по сборке и распределению I/O. Что бы
подробно изучить использование в SQL Server сборки и
распределения для повышения его производительность, прочтите
следующий документ:
Для операций с журналом транзакций, SQL Server использует
WriteFile вместо WriteFileGather. WriteFileGather используется
для I/O в операционной системе, и ограничен размером страницы.
Это ограничение подразумевает, что каждая запись в журнал
будет иметь размер не менее 4 Кб. Поэтому для журнала
используется WriteFile, что позволяет сократить размер записи
до границ сектора диска.
Весь I/O журнала транзакций и файлов баз данных SQL Server
выполняется с использованием структуры OVERLAPPED, которая
позволяет облегчить использование асинхронного I/O. Буферный
пул SQL Server и диспетчер файлов имеют очень сложные
внутренние механизмы для обслуживания I/O. Для поддержки
целостности данных во время асинхронных операций с I/O
используются соответствующие краткие блокировки для
чтения/записи. SQL Server использует запросы к Win32 API
следующим образом:
API
Типовое применение
CreateFile
Используется для того, чтобы создавать и открывать
базу данных и журнал. Флаги: FILE_FLAG_OVERLAPPED,
FILE_FLAG_WRITETHROUGH и FILE_FLAG_NO_BUFFERING
определяются для предотвращения неустойчивого
кэширования носителей.
WriteFile
В основном используется менеджером журналирования и
менеджером резервирования для обслуживания запросов I/O.
ReadFile
В основном используется менеджером журналирования и
менеджером резервирования для обслуживания запросов I/O.
WriteFileGather
В основном используется буферным пулом для записи
группы страниц (до шестнадцати страниц по 8 Кб в
группе).
ReadFileScatter
В основном используется буферным пулом для чтения
страниц в буферный пул. Может использоваться для
отдельных запросов страницы так же как и запросов
упреждающего чтения. Запросы упреждающего чтения обычно
используют 128 страниц для каждой группы, но могут
использовать и 1024 страницы, если это Microsoft SQL
Server Enterprise Edition
HasOverlappedIoCompleted
Используется для определения состояния запросов I/O.
GetOverlappedResults
Используется для определения успешности запросов
I/O.
Обратите внимание: Сортировка и операции спулинга,
для осуществления необходимых операции с I/O, совместно
используют некоторые механизмы буферного пула SQL Server и
диспетчера файлов. Также, обратите внимание, что SQL Server не
всегда обслуживает завершение I/O в рамках того же самого
рабочего потока, который отправлял этот запрос I/O. Завершение
I/O в SQL Server выполняется унаследованным рабочим потоком в
рамках того же самого User Mode Scheduler (UMS), в котором
запрос I/O был отправлен на исполнение. Внутренние механизмы в
SQL Server назначают подпрограммы повторного вызова, которые
будут вызываться при завершении I/O. Повторный вызов - это
специфический для SQL Server механизм, который не основывается
на сообщениях, подобных функциям ReadFileEx или WriteFileEx.
Например, если чтение страницы данных завершено, подпрограмма
повторного вызова проверит, что код возврата операционной
системы равен нулю (значение GetLastError), и это будет
гарантировать, что все байты были переданы правильно, что
выполнена проверка на ошибки оборванных страниц, и что
гарантируется правильный номер страницы, и исполнены все
другие разумные проверки.
Речь пойдёт о трёх основных механизмах, которые провоцируют
сброс страницы данных на диск. Однако, все они использует одну
и ту же встроенную подпрограмму работы с буферным пулом, с
помощью которой происходит передача данных:
Отложенная запись (least recently used - LRU и основанная
на вытеснении памяти)
Контрольная точка (на основании recovery - интервала)
Безотложная запись (базируется на нерегистрируемом
I/O)
Для эффективной записи при сбросе на диск используется
WriteFileGather. Это позволяет SQL Server связывать
последовательно расположенные грязные страницы в один запрос
на запись. SQL Server использует следующую
последовательность сброса на диск одной страницы:
На страницу накладывается краткая блокировка, что
позволяет предотвратить возможные её последующие
изменения.
Гарантированный сброс на диск долговременного носителя
записей журнала транзакций, относящихся к хранимому в
заголовке страницы LSN.
Установка правильных параметров для вызова
WriteFileGather.
SQL Server использует следующую последовательность
действий, при необходимости сброса на диск следующей страницы,
и повторения этих действий для нескольких страниц (до 16-ти
страниц в целом, включая первую страницу).
Выполняется поиск по хэшу (hash lookup) следующей
страницы. Например, если страница, которая сбрасывается на
диск имеет номер 100, SQL Server ищет в массиве буферного
хэша страницу с номером 101.
Если эта страница не найдена, то устанавливается конец
цельного блока I/O, и отправляется запрос на этот I/O.
Если страница будет найдена, на неё налагается краткая
блокировка, что позволяет предотвратить её дальнейшие
изменения, т.к. она может быть "грязной".
Выполняется проверка, чтобы убедиться, что страница
является "грязной" и должна быть сохранена. В противном
случае снимается краткая блокировка и объявляется конец
непрерывного блока I/O, как это задано и представлено
асинхронным запросом на I/O.
Если страница "грязная", то всё повторяется с шага
1.
После того, как будет определен набор страниц, которые
нужно сбросить на диск, вызывается функция WriteFileGather,
которая отправляет (Async / OVERLAPPED) запрос на I/O с
привязкой к функции повторного вызова, которая завершит
операции I/O. Когда SQL Server определяет, что
HasOverlappedIoCompleted возвращает TRUE, используется функция
GetOverlappedResults, которая собирает в системе информацию о
завершении операции, и вызывает функцию повторного вызова.
Функция повторного вызова делает соответствующее заключение об
успешности операции I/O и снимает краткие блокировки на каждой
из задействованных страниц.
Программа отложенной записи в SQL Server 2000 и SQL Server
7.0 пытается определить расположение до 16-ти уникальных
страниц нуждающихся в перемещении для возврата их в число
свободных страниц. Если счётчик ссылок страницы дойдёт до
нуля, она может быть возвращена в качестве свободной. Если
страница отмечена как "грязная", её записи журнала и страницы
данных будут сброшены на диск. Таким образом, программа
отложенной записи может единовременно сбросить на диск 16*16
страниц. Это будет достаточно эффективно, потому что многие из
этих страниц останутся в буферном пуле SQL Server, но будут
находиться после этого в состоянии - "свободна". I/O
выполняется в фоновом режиме относительно основного SPID
(идентификатор серверного процесса). Когда программа
отложенной записи нуждается в дополнительных буферах для
своего списка свободных страниц, нет нужды сбрасывать на диск
буфера, просто выполняется высвобождение хэша и возврат в
список свободных страниц.
Процесс контрольной точки в SQL Server 2000 периодически
проходит по буферному пулу, анализирует буферы, которые
содержат страницы указанной базы данных, и сбрасывает на диск
долговременного носителя все "грязные" буферы. Это делает
короче процесс регенерации (recovery), потому что операции
отката назад потребуют для своего исполнения меньших
физических затрат. Как говорилось ранее, процесс
контрольной точки использует тот же самый подход к I/O,
отправляя до 16 страниц в одном запросе на I/O. Когда запрос
на I/O отправлен (OVERLAPPED), контрольная точка не ждет
немедленного исполнения каждого I/O. Контрольная точка
продолжает отслеживать посылаемые и исполняемые запросы на
I/O, но пытается при этом поддерживать высокий уровень
исполнения незавершённых запросов на I/O (например, 100
постоянно обслуживающихся не завершённых запросов на запись).
Это повышает производительность I/O и уменьшает время
исполнения контрольной точки. До появления WriteFileGather,
SQL Server сортировал буферы обслуживаемой базы данных в
порядке страниц и также в порядке страниц создавал запросы на
I/O. Это порождало множество физических запросов I/O, потому
что порядок страницы для сброса не соответствовал непрерывному
расположению в памяти. Однако, довольно часто механизмы
подсистем физического уровня предоставляли страницам такое
физическое местоположение, которое располагало их в
непосредственной близости, что способствовало достаточно
быстрому исполнению запросов на I/O. В более позднем
дизайне, элеваторный поиск может быть проблематичен. Сбор
нескольких запросов на I/O в порядке страниц обычно приводит к
порядку, близкому к порядку на диске. При интенсивной нагрузке
подсистем множеством запросов на I/O, упорядоченных таким
образом, дисковод может обслужить эти запросы на I/O до
запросов, которые могли быть не завершены до этого. С
появлением WriteFileGather, SQL Server может перемещать
буферный пул, не требуя какого либо физического соотношения с
порядком расположения страниц на диске. Собирая группы по 128
Кб (шестнадцать страниц по 8 Кб), SQL Server может передать
блоки данных, используя для этого намного меньше физических
запросов на I/O. Это позволяет процессу контрольной точки
поддерживать хорошую скорость, и в то же время для запросов на
I/O, которые носят случайный характер, поддерживать
элеваторный поиск, который может повлиять на другие операции
I/O. Все базы данных, кроме tempdb, обслуживаются контрольной
точкой. Tempdb не требует регенерации (она пересоздаётся при
каждом запуске SQL Server), поэтому сброс на диск страницы
данных не оптимален для tempdb, и SQL Server старается
избегать этого. Контрольная точка защищает систему от
наводнения операциями I/O, преобразуя их в последовательную
форму посредством процессов контрольной точки. Единовременно,
исполняться может только одна контрольная точка. Процессы
контрольной точки и программа отложенной записи
взаимодействуют друг с другом, чтобы управлять внутренними
механизмами очереди на I/O.
Microsoft SQL Server 2000 использует безотложную запись для
страниц данных, связанные с не регистрируемыми операциями
(обычно это bulk insert / select into). Это предоставляет
возможность экземплярам I/O асинхронно сохранить на диск
"грязные" страницы без нежелательного образования больших
частей грязного буферного пула. Процессами контрольной точки
используется тот же самый механизм отправки запросов на
операции I/O, как и у отложенной записи. Microsoft SQL
Server 7.0 не имеет возможности выполнять безотложную запись,
вместо этого, контрольная точка проходит во время завершения
транзакций, чтобы сбросить на диск все буфера базы данных. Это
может спровоцировать много нерегистрируемых операций, которые
будут преобразованы в последовательную форму, потому что может
быть активна только одна контрольная точка. Важно:
Отложенная запись, контрольная точка и безотложная запись не
ожидают немедленного завершения I/O. Они всегда отправляют
запросы на I/O посредством WriteFileGather с опцией
OVERLAPPED, и продолжают работать дальше, чуть позже проверяя
успешность завершения I/O. Это позволяет SQL Server
максимизировать ресурсы процессоров и I/O для соответствующих
задач.
Штатная операция завершения работы сервера баз данных
запускает процесс контрольной точки для всех баз, закрывает
все внутренние процессы проверки структур баз данных и
завершает процесс SQL Server. Интервал регенерации
(recovery interval) управляет поведением контрольной точки.
Когда этот интервал увеличивается, между вызовами контрольной
точки в памяти появляется больше "грязных"
страниц. Современные версии Microsoft Windows рассчитывают,
что завершение работы SQL Server успешно выполнится за 60 -
120 секунд.
Работа в кластере может повлиять на время завершения работы
сервера баз данных.
Если в отказоустойчивом кластере превышено стандартное
время завершения работы экземпляра на одном из узлов,
кластер может принудительно завершить работу ресурса SQL
Server, а также систем, участвует обеспечивающих
отказоустойчивости.
Кластерный ресурс SQL Server будет отмечен состоянием
отказа SQL Server. При этом, в соответствии со сценарием
перемещения группы, кластерный процесс физически передаст
отказавшие ресурсы под управление другим узлом.
Неумелый выбор интервала регенерации может привести к
тому, что исполнение контрольной точки займёт больше
времени, превысив заданные лимиты, и спровоцировав
агрессивную реакцию системы поддержки отказоустойчивости.
Агрессивные сценарии поддержки отказоустойчивости, таким
образом, могут оказаться опасны.
Microsoft строго рекомендует использовать установленные
по умолчанию значения для интервала регенерации, это
гарантирует оптимальную метрику регенерации и будет
правильно работать с учётом типовых ограничений кластерных
ресурсов. Если интервал регенерации превышает 60 секунд,
велика вероятность того, что работающий на кластере
экземпляр будет переведён агрессивным сценарием в автономное
состояние. Хотя применение агрессивных сценариев поддержки
отказоустойчивости и имеет множество плюсов, они
нежелательны. Если процесс регенерации сопряжён со
значительными сложностями, вызванными большим числом
транзакций, Microsoft рекомендует оптимизировать размещение
баз данных, физическое размещение их файлов и физических
каналов I/O, а не корректировать интервал регенерации, в
целях повышения его производительности.
После корректировки интервал регенерации могут возникнуть
несколько побочных эффектов. Обдумайте их тщательно перед тем,
как корректировать интервала регенерации.
Время жизни "грязных" страниц - страница считается
"грязной", когда имели место изменения её данных. Грязная
страница не может быть удалена из буферного пула SQL Server,
пока вначале связанные с ней записи журнала транзакций и затем
сама страница не будут записаны непосредственно на
долговременный носитель. Увеличение интервала прохождения
контрольной точки (после увеличения интервала регенерации) под
высокой нагрузкой системы провоцирует вытеснение обработки
грязных страниц под управление кода программы отложенной
записи. Это может привести к полной деградации
производительности, потому что отложенная запись не
предназначена для исполнения действий, подобных контрольной
точке. Программа отложенной записи действительно исполняет
соответствующие её действия с грязными страницами, чтобы
обеспечить гарантию целостности данных и высвобождение
свободного места, но, в отличие от процесса контрольной точки,
она не приспособлена для сокращения времени жизни грязных
страниц. Контрольные точки позволяют более продуктивно
сохранять грязные страницы. Передача функций контрольных точек
программе отложенной записи увеличит время ожидания, потому
что отложенная записи вынуждена исполнять I/O для отложенных
буферов, вместо простых операций в памяти, обеспечивающих
свободное место. Если Вы изменили интервал регенерации, нужно
проверить показания счётчиков производительности, относящиеся
к программе отложенной записи.
Продолжительность контрольной точки - Увеличение
интервала регенерации может привести к увеличению в
оперативной памяти числа грязных страниц. Чем больше грязных
страниц, тем дольше контрольная точка будет сбрасывать их на
диск во время прохождения по буферному пулу SQL Server.
Увеличение продолжительности контрольной точки не является
проблемой, но потенциально может увеличить интервал
регенерации и повысить нагрузку на дисковую подсистему во
время этого интервала.
Продолжительность регенерации - Увеличение интервала
регенерации может привести к увеличению времени регенерации.
Если SQL Server не штатно завершает свою работу (неожиданное
завершение процесса или, например, происходит падение
напряжения), во время следующего старта, менеджер регенерации
обеспечивает правильность состояния транзакций базы данных.
Если контрольная точка запускается не часто, и это приводит к
значительному увеличению числа грязных страниц, не штатное
завершение потребует для менеджера регенерации исполнение
большого числа откатов и проверки транзакций, необходимых для
возврата базы данных к непротиворечивому состоянию транзакций.
Основным фактором, влияющим на производительность этой
операции, является то, что буферный пул SQL Server будет
"холодным" (в памяти не будет страниц) во время регенерации.
Процедура восстановления должна будет считать в память все
соответствующие страницы базы данных и сделать необходимые
изменения. Это может увеличить время ожидания регенерации, что
является нежелательным для промышленных применений. Увеличение
интервала регенерации часто приводит к потерям в
производительности и к дискриминации требований к доступности
приложений. Например, предположим, что при штатной загрузке
системы контрольная точка каждую минуту должна сбрасывать на
диск 250 Мб грязных буферов. В соответствии с алгоритмом
работы контрольной точки, при интервале регенерации в 10
минут, на диск будет сброшено 2500 Мб данных, если все другие
влияющие факторы останутся постоянными. Если продолжительность
контрольной точки превысить величину интервала, тогда для
этого дискового массива стоит увеличить число дисков, что бы
все страницы успевали обрабатываться, и возможности
параллельной обработки были задействованы полностью. Однако,
2500 Мб грязных страниц сами по себе потребуют достаточно
больших затрат для поддержания удовлетворительной работы
процесса регенерации.
Microsoft SQL Server 2000 использует несколько моделей
резервирования баз данных: Full, Bulk-Logged и Simple. Рабочая
нагрузка прикладной системы при разных моделях резервирования
может получить разное поведение I/O. Приложение, аппаратное
решение и модель резервирования должны выбираться из бизнес -
требований к развертываемой системе по резервированию и
восстановлению.
Записи журнала сбрасываются на диск аналогично страницам
данных. За запись в журнале базы данных отвечает менеджер
журнала транзакций. Вы можете сделать запрос к таблице
sysprocesses, чтобы увидеть относящиеся к журналу транзакций
SPID. Когда запрашивается сброс на диск всех записей
журнала до какого-нибудь номера LSN по требованию одного из
системных потоков, такой запрос будет поставлен в очередь
менеджера журнала. Процесс будет ждать ответа менеджера о том,
что I/O завершился успешно. Менеджер журнала просматривает
очередь и форматирует запросы. После этого он организует I/O
кратными размеру сектора диска блоками. I/O передаётся
функции WriteFile, использующей OVERLAPPED (асинхронные)
механизмы. После этого, менеджер журнала возвращается к
обслуживанию других, поставленных в очередь запросов. Когда
I/O будет закончен, отрабатывает завершающая его подпрограмма,
которая проверяет успешность записи. Если запись прошла
успешно, ожидающий процесс получит об этом сообщение, и может
продолжить свои операции. На этой стадии, порядок записи
является критичным. Поскольку одному журналу может быть
направлен запрос на несколько операций записи, должен
соблюдаться порядок обслуживания LSN. Например, если
страницы 50, 100 и 200 изменяются в разных транзакциях, и
сначала изменяется страница 50, потом 100, а затем 200. Тогда,
при получении запросов на сброс LSN для страниц 50, 100 и 200,
он будет выполнен в том же самом порядке. Если записи в
журнале для страниц 50 и 200 будут сброшены на диск
долговременного носителя, считается выполненным только сброс
LSN для страницы 50, и SQL Server сбросит на диск только
страницу 50. LSN для страницы 100 должен быть сброшен на диск
долговременного носителям прежде, чем LSN 100, и только потом
LSN 200 может считаться сброшенным на диск (журнал
фиксируется). Порядок записи - ключевой элемент поддержки
целостности данных в SQL Server.
Для упреждающего чтения SQL Server 2000 использует функцию
ReadFileScatter. Для поиска страниц данных, которые могут
скоро понадобиться, SQL Server использует довольно сложные
алгоритмы. Например, если выполняется запрос, который может
использовать индекс, может быть принято решение о
необходимости упреждающего чтения соответствующих ему строк из
страниц фактических данных, которые необходимы для получения
требуемой выборки. Поскольку элементы индекса
идентифицированы, SQL Server может генерировать OVERLAPPED
(async) операции I/O для страниц данных, которые планируются в
следующих шагах плана исполнения запроса. Это демонстрирует
то, как запрос использует упреждающее чтение для поискового
оператора - bookmark lookup. В этом примере
продемонстрирована только одна из возможностей применения
упреждающего чтения, которые задействованы в SQL Server.
Извлечение во время поиска по индексу I/O страниц данных,
повышает полезность утилизации в системе CPU и I/O. Зачастую
этот I/O завершается к тому времени, когда это необходимо, и
следующие шаги плана исполнения уже имеют прямой доступ к
необходимым данным, располагающимся уже в памяти, и не нужно
прерываться на ожидании извлекающего их I/O. Когда
вызывается упреждающее чтение, оно может охватить от 1 до 1024
страниц. Для большинства редакций SQL Server глубина запроса
одного упреждающего чтения ограничивается 128 страницами.
Однако, Microsoft SQL Server Enterprise Edition поднимает это
ограничение до 1024 страниц. SQL Server использует
следующие шаги для организации упреждающего чтения:
Получение необходимого количества буферов из свободной
области.
Для каждой страницы:
Определение статуса нахождения страницы в оперативной
памяти (in-memory), путём хеш-поиска.
Если обнаружено, что страница уже находиться в памяти,
организуется запрос на упреждающее чтение с немедленным
возвратом буфера в свободную область после завершения
I/O.
Определяются параметры запроса на I/O для вызова
функции ReadFileScatter.
Организуется краткая I/O блокировка, для защиты буфера
от доступа на время операции.
Если хеш-поиск не обнаружил страницу, она вставляется в
хеш-таблицу.
Исполнение операций функции ReadFileScatter по чтению
данных.
Когда закончится операция I/O, каждая страница проверяется
на соответствие её номера и возможность обрыва страниц. Кроме
того, выполняются и другие проверки целостности и безопасности
данных. Краткая I/O блокировка снимается, и страница
становится доступна для использования, если она расположена в
цепи хеширования. Если выясниться, что страница уже находиться
в памяти, страница немедленно будет возвращена в свободную
область. Этот процесс демонстрирует ключевые факторы I/O
экземпляра SQL Server. Упреждающее чтение возможно для
страниц, которые уже могут находиться в памяти или не
распределены. Поскольку в SQL Server поддерживается
буферизация в оперативной памяти (in-memory buffers) и цепочки
хеширования, SQL Server должен отслеживать состояние страниц.
Важно, что процесс упреждающего чтения даёт возможность
перекрытия запросов на чтение и запись на аппаратном
уровне. Если страница уже находится в памяти, когда
отправлен запрос на упреждающее чтение, непрерывное чтение все
еще остаётся необходимым и более быстрым, чем разбивка
запросов на чтение на множество физических запросов. SQL
Server практически не использует такое чтение для
запрашиваемой страницы, но многие из окружающих её страниц
могут его использовать. Однако, если в момент запроса на
чтение будет выполняться операция записи, соответствующая
подсистема должна определить, какой из этих типов чтения будет
возвращён. Некоторое реализации возвращают текущую версию
страницы до того, как будет закончена запись. В других
реализациях, чтение ожидает, пока запись не будет завершена, а
многие другие реализации возвращают комбинацию, показывающую
частично новые и старые данные. Ключом к пониманию того, как
это реализовано в SQL Server, является то, что чтение не
используется, но подсистема сервера должна поддерживать
достоверный образ для следующих операций чтения.
Осуществляемая запись, в момент её завершения, должна
формировать следующий образ операциям чтения, предоставляемый
для дальнейшего использования в SQL Server. Не путайте
упреждающее чтение с параллельными планами исполнения
запросов. Упреждающее чтение происходит независимо от выбора
вариантов параллельного плана запроса. Параллельный план может
управлять нагрузкой I/O, потому что разделяет её между
несколькими потоками, а упреждающее чтение выполняется и для
последовательных и для параллельных планов. Для гарантии того,
что параллельные потоки не работают с одним и тем же набором
данных, SQL Server использует подпрограмму - поставщика
параллельных страниц, который помогает сегментировать запросы
данных. В SQL Server реализована расширенная диагностика,
которая заранее уведомляет об отказах при чтении. На сайте
Microsoft есть статья, которая рассказывает, как включить
такую диагностику и какие для этого нужно использовать
команды.
Подсистема I/O в SQL Server 2000 на уровне ядра
запрограммирована на обеспечения всех обязательных требований
по поддержке целостности данных. Если ваша система полностью
адекватна требованиям, представленным в следующих далее
разделах статьи, тогда SQL Server будет способен выполнять
требования ACID для ваших баз данных.
Любая операция в системе с SQL Server должна обеспечить
предъявляемые к долговременным носителям требования для
журналов транзакций и файлов баз данных. Если в системе
используются кэширующие дисковые контроллеры без автономной
батареи или возможно дополнительное кэширование записываемого
на диск, это не безопасно для экземпляра SQL
Server. Убедитесь, что ваша система правильно использует
кэширование и обеспечивает безопасный транспорт данных с
долговременным носителем.
SQL Server разработан с учётом необходимости поддержки
протокола WAL, который был описан выше. В поддержке этого
протокола основную роль играет среда исполнения, которая
должна поддерживать порядок записи. Для любой системы,
которая использует удалённое зеркалирование, порядок записи
является критичным для поддержания последовательности меток
времени. Многие поставщики систем удалённого зеркалирования
реализуют в своих системах логику поколений, которая призвана
поддержать физический порядок записи, даже когда операции
записи передаются между разными кэшами с использованием
дополнительных протоколов.
В SQL Server блоки по 8 Кб должны использоваться как единый
блок данных. Системы, которые разбивают I/O, должны
настраиваться таким образом, чтобы они не раскалывали запросы
I/O на блоки меньшего размера. Некоторые динамические диски и
менеджеры томов могут устанавливать размер блока, равный
размеру кластера, которые могут быть меньше 8 Кб или около 8
Кб. Такие системы могут разделить запрос SQL Server на I/O
между несколькими физическими компонентами системы. При этом,
они могут привести к появлению оборванных страниц, и этим
нарушить порядок следования записи. Убедитесь, что ваша
система не дозволяет разбиения данным по указанной причине, и
не приводит к появлению оборванных страниц.
Проблемы, ловушки и примеры, описанные в этой главе,
являются проблемами, с которыми сталкивалась служба поддержки
Microsoft и сотрудники департамента разработки SQL Server.
Многие из них привели к изменениям в конфигурации и/или другим
изменениям, например, в программном обеспечении сервера,
драйверах или на других уровнях, а также к исправлениям вне
SQL Server. Поскольку могут возникнуть совершенно разные
проблемы и в сфере долговременных дисковых носителей
задействовано множество их изготовителей, Microsoft
рекомендует обращаться к вашим поставщикам аппаратного и
программного обеспечения за консультациями по поводу того,
является ли Ваша конкретная реализация приемлемой для
взаимодействия с SQL Server 2000.
Что такое чтение устаревших данных на аппаратном уровне и
чем оно отличается от оборванной записи? Поскольку чтение
устаревших данных может проявиться как оборванная запись, или
оборванная запись может появиться как чтение устаревших
данных, стоит явно определить эти термины. Следующие
определения предполагают, что все запросы операционной системы
исполняются успешно и приложением непривилегированного режима
правильно используются соответствующие API. Чтение
устаревших данных (stale read) происходит тогда, когда по
данным, возвращаемым через запросы ReadFile или
ReadFileScatter, не предоставляется информация об успешности
последней операции записи. Оборванная запись (lost write)
определяется тем, что данные, посланные через WriteFile или
WriteFileGather, никогда не попадают на долговременный
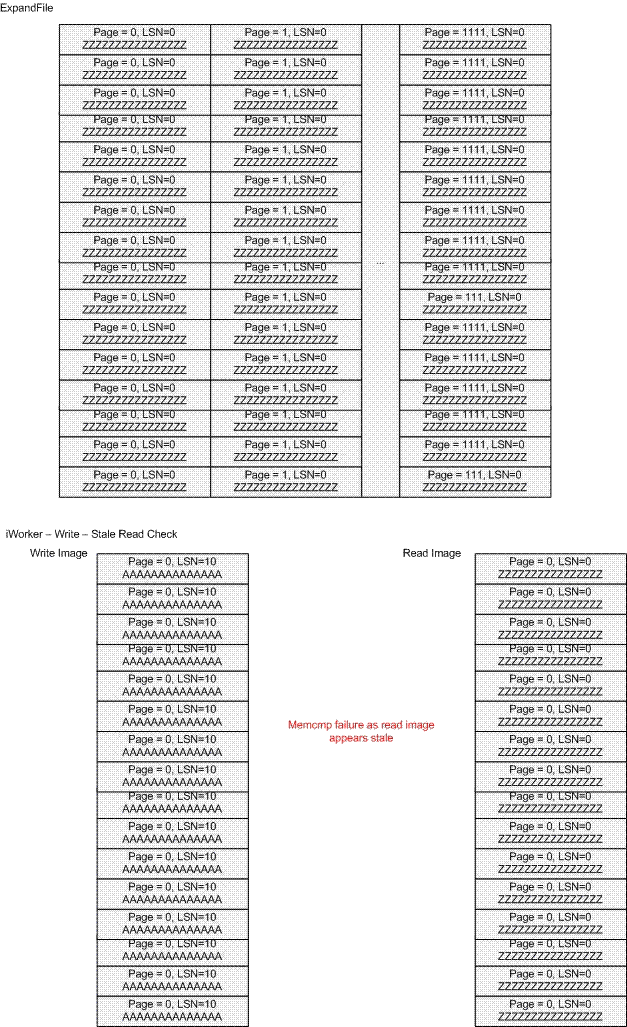
носитель. Посмотрите внимательно на следующий ниже рисунок,
исходя из допущения, что долговременные носители можно
абстрагировать к образу ExpandFile.
Рисунок
2
Чтение устаревших данных возникает тогда, когда
изображённая на рисунке запись, показанная, как заполнение
символом "A", будет успешно записана на диск, заменяя
изначальную, с символами "Z". Однако, при следующем чтении
этих же байт (смещение) в файле, будет всё еще возвращаться
значение с "Z", а актуальные на этот момент данные с символами
"A" будут недоступны.
чтение устаревших данных имеет место тогда, когда
долговременный носитель содержит данные с "A", но аппаратный
кэш возвращает данные с "Z".
оборванная запись имеет место тогда, когда, когда
долговременный носитель содержат символы "Z", а запись
фактического значения с "A" не была доведена до успешного
завершения.
В этом примере мы рассмотрим возможную ситуация чтения
устаревших данных. Вспомним, что упреждающее чтение в SQL
Server читает большими блоками, но при этом игнорируются
страницы, состояние которых неизвестно. После завершения
чтения, буфер будет немедленно возвращён в свободную область,
и страница считается сохранённой к началу I/O запроса на
упреждающее чтение. В нашем примере, предположим, что
страницы 107 и 108 находятся в буферном пуле SQL Server и
считаются грязными.
Осуществляется запись страницы 107
По запросу программы отложенной записи.
Осуществляется запись страницы 108
По запросу программы отложенной записи
Завершается запись страницы 107
Завершается запрос на I/O, а программ отложенной
записи удаляет страницу из кэша и размещает её буфер в
свободную область.
Поступает запрос на чтение страниц 100 - 115.
Для данных используется упреждающее чтение. В памяти
найдена только страница 108. Упреждающее чтение
осуществляет необходимые действия по буферизации но
хеширование не выполняется, поскольку данные уж
находятся в памяти.
Чтение завершено
Завершение чтения. Ключевой момент: данные страницы
108 неизвестны, поскольку они ещё не записаны на
аппаратном уровне. SQL Server не плодит дубликатов,
поэтому задействованный буфер будет возвращён в
свободную область непосредственно по завершении
чтения. Примечание: Эта версия страницы 108 в
настоящее время хранится в аппаратном кэше упреждающего
чтения.
Завершается запись страницы 108
BUG: Аппаратный кэш упреждающего чтения ещё хранит
эту страницу. Программа отложенной записи выдает
страницу 108 из кэша и размещает её буфер из свободной
области.
Поступает запрос на чтение страницы 108
Правильным было бы выполнить физическое чтение, но из
аппаратного кэша упреждающего чтения будет извлечён
образ устаревших данных, а не его версия на
диске.
Инструментарий, который включается флагом трассировки
-T818, отслеживает операции записи последних 2048 страниц. При
успешном завершении I/O записи (верный ID страницы, успешная
передача байт, и соответствующие коды ошибок операционной
системы), DBID, ID страницы и LSN помещаются в закольцованном
буфере. В случае возникновения отказа, будет выставлена ошибка
823. Когда обнаружена ошибка 823 или 605, SQL Server
просматривает кольцевой буфер, ища там значение LSN, которое
было зафиксировано для последней, записанной страницы. Если он
некорректно, об этом в файл регистрации ошибок SQL Server
добавляется дополнительная информация, которая указывает тип
ошибки, а также ожидаемый и обнаруженный номера
LSN. Дополнительная информация об LSN, о котором идёт речь,
появится в файле регистрации ошибок SQL Server. Возвращаемый
после чтения LSN явно старше (устаревший), чем значение,
которое соответствует последней записи.
SQL Server has detected an unreported OS/hardware level read or write
problem on Page (1:75007) of database 12
LSN returned (63361:16876:181), LSN expected (63361:16876:500)
Contact the hardware vendor and consider disabling caching mechanisms to
correct the problem
С появлением SQL Server 2000 Service Pack 4 (SP4), дизайн
-T818 лучше использует хэш-таблицы. Стало доступно более 2048
записей в хэш-памяти для 32-битных редакций, а 64-битных даже
ещё больше. Поскольку мы имеем реализацию в виде
хэш-таблицы, проверка чтения устаревших данных может
выполняться при каждом чтении, а не только для тех страниц,
которые выявлены по предыдущим ошибкам 823 или 605. Эта
проверка подобна другому стандарту, по которому проверяется ID
объекта страницы (605) и состояние ошибки номера страницы
(823). Поскольку проверка выполняется при каждом чтении, это
позволяет охватить даже те ситуации, когда ID страницы и ID
объекта являются правильными, но строки страницы были
повреждены. Например, если была вставлена строка, страница
была сброшена на диск и произошло чтение устаревших данных
(строки отсутствуют на диске), ID объекта и ID страницы будут
правильными, и до появления SP4, возможно, чтение устаревших
данных не было бы зафиксировано. Новый дизайн обнаружит
несоответствие LSN и выставит ошибку 823.
Страницы базы данных SQL Server занимают 8 Кб, в то же
время, типичный размер передаваемого на аппаратном уровне
блока равен 4 Кб, если используются 512-байтные секторы диска.
Когда Вы используете конфигурацию с RAID, незаполненные части
могут проявиться, как оборванное чтение. Синхронизация чтения
и записи может внести путаницу для разных дисков, так что
могут быть извлечены частично старые и частично новые данные.
Опять, ошибка состоит в том, что после записи, не все части
кэша упреждающего чтения были до конца переданы на диск. Не
правильный образ сохраняется в аппаратном кэше упреждающего
чтения, пока он не будет извлечён принудительно.
Есть операции, которые принудительно сбрасывают на диск
аппаратный кэш. Сброс на диск может разрешить ошибки, если они
являются переходными. Существует не много методов, которые
могут быть вызваны в SQL Server, что бы достичь этого
эффекта:
Запуск dbcc dropcleanbuffers, после чего будут
удалены все буферы из буферного пула.
Запуск dbcc checkdb для базы данных, имеющих
соответствующие проблемы.
Эти методы позволяют исправить проблему перехода за счёт
повторения не правильных действий. Данная методика заставляет
checkdb создать большое количество запросов на чтение, которые
вынуждают прокручивать аппаратный кэш. Эта прокачка кэша
выбирает из аппаратного кэша кэшируемые данные секторов и
провоцирует правильное физическое чтение. В результате, будет
получен правильный образ и SQL Server чудесным образом
исправит проблему.
Программа стрессового тестирования SQLIOStress (начиная с
версии 4.00.020) содержит специальный код, позволяющий быстро
обнаружить проблемы чтения устаревших данных и оборванную
запись. Добавление параметра (-H) провоцирует утилиту на более
агрессивную симуляцию упреждающего чтения и позволяет быстро
вызвать проявление указанных проблем. Представленный ниже
фрагмент отчёта о работе SQLIOStress с включённым параметром
(-H), демонстрирует наличие проблем у тестируемого дискового
контроллера. Когда проявляется проблема, запись о ней и сам
читаемый образ сохраняются в журнал работы, а так же
результаты запросов к API, которые при этом были сделаны.
Во время работы SQL Server обнаруживает много разных типов
проблем с I/O или нарушений в целостности данных. Обнаруженные
проблема I/O или нарушения целостности данных сохраняются SQL
Server в виде сообщений об ошибках. Наиболее типичные ошибки -
605, 823, 624 и записи об отказах при восстановлении. Не
поддаются обнаружению в SQL Server только несколько ситуаций.
Эти ситуации проявляются как логические проблемы данных и
обычно генерируют неожиданные исключения на уровне
приложения.
Ошибки 605 и 823 проявляются непосредственно на этапе
исполнения проверки правильности страниц и идентификаторов
объектов. Это простые проверки - ловушки на этапе исполнения,
которые не влияют на производительность. Проблема состоит в
том, что чтение устаревших данных повышает вероятность
проявления большого количества потенциально возможных
ошибок.
Во многих случаях (ошибки 6xx), данные могут потерять
логическую согласованность (например, при ошибке 624:
Could not retrieve row from page by RID because the
requested RID has a higher number than the last RID on the
page. %S_RID.%S_PAGE, DBID %d). В качестве примера, можно
рассмотреть случай, когда в таблицу вставляется новая строка,
но имеет место чтение устаревших данных со страницы индексов,
в результате чего, будет потеряна вставка в индекс. Это будет
выглядеть так, как будто индекс не изменился, и строк данных в
таблице будет больше, чем соответствующих строк в индексе. Это
может говорить о том, что ключ индекса выбран неудачно. Если
эта часть таблицы - хип, тогда реляционные идентификаторы
(RID) могут оказаться неправильными, потому что страницы
фактических данных сгруппированы по-другому. Вы можете
придумать и другие, приводящие к ошибкам сценарий, если
рассматривать реляционные отношения данных. Если одна из
страниц становится жертвой чтения устаревших данных, это может
говорить о том, что вставка реально не имела места.
Проявляться это может в виде не соответствия ожидаемому числу
записей или нарушений первичных и внешних ключей (PK/FK). Всё
это очень похоже на то, как будто бы дебет или кредит
пользователя не сходится. Когда подозревается наличие
подобных проблем в данных, круг потенциальных источников
проблем довольно широк. Данные могут оказаться поврежденными
после проверки DBCC checkdb. Это могло быть результатом
проблем на этапе исполнения, когда RID индекса вдруг начинает
указывать на не те области данных, а это уже может породить
множество других проблем, например, исключений или
остановок.
Нарушение целостности данных или проблемы с их целостностью
могут появиться при попытке выполнения операции
восстановления. Например, чтение устаревших данных может
привести к сбою во время восстановления журнала
транзакций. Как было подчёркнуто ранее, LSN должен быть
уникален в рамках одной базы данных. В случае чтения
устаревших данных, повышается вероятность обнаружения двух
разных записей в журнале с одинаковыми LSN. Процесс
регенерации SQL Server обнаружит это, воспримет как проблему,
и прервёт операцию регенерации (recovery). Это явный признак
того, что страница была изменена, сброшена на диск и тут же
читалась. Однако, последнее изменение не было обнаружено из-за
чтения устаревших данных. Повторное изменение будет
использовать старый LSN, и возможность возвращения правильной
страницы будет потеряна. Обратите внимание: Это важно
потому, что чтение устаревших данных может привести к тому,
что резервное копирование не будет позволять решить задачу
корректного восстановления данных в случае необходимости.
Репликация может использовать журнал транзакций как
источник данных. Когда из-за проблем, подобных чтению
устаревших данных, журнал транзакций будет повреждён, это
приведёт к повреждению самого источника данных для репликации.
Повреждение этого источника может привести к проблемам с
логической последовательностью тиражируемых
данных. Например, когда используется репликация, проблема
может затронуть несколько компьютеров. В сценарии репликации
слиянием, если на одном из компьютеров изменения потеряны
из-за проблем с чтением устаревших данных, это может затронуть
механизмы, с помощью которых репликация слиянием обслуживает
топологию тиражирования данных. Возможно разное проявление
порождённых этим проблем, включая отказы сеансов
синхронизации.
Многие реализации программного обеспечения резервного
копирования, антивирусные программы и других приложения,
реализованы в виде промежуточных драйверов между подсистемой
I/O и операционной системой. Это позволяет перехватывать
запросы на I/O и обрабатывать их соответствующим образом.
Неправильная работа таких драйверов может стать причиной
чтения устаревших данных или прерванной записи. Часто,
проблемы такого типа требуют воспроизводства в тестовой среде
и значительных усилий по отладке на уровне ядра, что бы
определить первопричину возникновения проблем, которые могут
напоминать проблемы с привязанными к драйверу пакетами
ввода-вывода (IO Request Packet). Всё это может отнимать много
времени и существенно осложнять поддержку работы
приложения. Microsoft рекомендует разработать безопасную
стратегию резервирования, но Вы также должны убедиться, что
программное обеспечение I/O разработано в соответствии с
требованиями к Microsoft SQL Server.
В SQL Server весьма распространены проблемы с
промежуточными драйверами, которые используются операционной
системой, и из-за которых I/O становится привязанным к
промежуточному драйверу и при этом, не обеспечивается средств
регистрации или уведомления об ошибках. Например, служба
поддержки SQL Server столкнулся с одной такой проблемой в
высокопроизводительной дисковой подсистеме, которая пыталась
балансировать запросы на I/O между несколькими Host Bus
Adapters (HBA). В программном обеспечении был дефект, который
приводил к прерыванию I/O. SQL Server бесконечно ожидал
окончания I/O, записав в журнале ошибок о том, что он выставил
краткую I/O - блокировку. Важно: Microsoft рекомендует,
чтобы Вы оценили применимость каждого используемого в системе
промежуточного драйвера, что бы он выдавал удовлетворительную
диагностику проблем и не вредил работе СУБД.
В SQL Server хорошо развиты возможности асинхронного I/O,
что позволяет повысить утилизацию используемых им ресурсов.
Служба поддержки SQL Server нашла решение для большинства
проблем, порождаемых некоторыми промежуточными драйверами,
мешавшими асинхронному I/O. Теперь от промежуточного драйвера
требуется, чтобы запрос на I/O был завершён до того, как
управление снова будет передано SQL Server. Это легко
реализуется, если контролировать длину очереди к дискам. Во
время работы, SQL Server обычно использует несколько запросов
на I/O. Когда I/O становится синхронным, очередь к дискам
часто порождается одним большим запросом на I/O, а это
порождает в SQL Server лишние блокировки. Поскольку
показания счётчика disk sec/transfer time не являются
статичными, использовать его нужно учитывая этот факт. Когда
на диск направляется не много запросов I/O, disk sec/transfer
показывает хорошую скорость. Чем больше длина очереди к диску,
тем больше разнообразие поведения disk sec/transfer. Однако,
SQL Server умеет определять, что в результате асинхронного
характера I/O, более длинные очереди к дискам и несколько
большие значения disk sec/transfer могут в итоге
способствовать повышению производительности и лучшему
использованию ресурса.
Когда в системе присутствуют промежуточные драйверы, они
имеют прямой доступ к данным I/O. Поэтому, целостность данных
может быть скомпрометирована не правильным поведением этих
драйверов. Убедитесь, что ваши промежуточные драйверы
совместимы с Microsoft SQL Server. Важно: Если Вы
наблюдаете проблемы со стабильностью I/O или его скоростью,
служба поддержка Microsoft SQL Server может рекомендовать Вам
отключить промежуточные драйверы, что бы проверить результаты
работы без их влияния. Нужно помнить, что единственным
надёжным способом отключения промежуточных драйверов является
их деинсталляция.
Windows позволяет сжимать файлы данных или криптовать их,
устанавливая соответствующие атрибуты файлов. Подробности о
поддержке каждой из этих опции SQL Server 2000 будут
представлены в этой главе.
Windows может сжимать расположенные на диске файлы, что
позволяет экономить занимаемое ими место. Сжатие не
поддерживается в SQL Server 2000 или его предыдущих версиях.
Проблема в том, что когда используется сжатие, данные файла
обрабатываются операционной системой большими кусками
(например, во 64 Кб). Поэтому, когда SQL Server изменяет
страницу данных в 8 Кб, в действительности система работает с
большей порцией данных и перезаписывает её. Такая
перезапись данных является нарушением протокола WAL, потому
что данные, уже сохранённые на диске будут перезаписаны, и
таким образом нарушается правило порядка записи. Перезапись
может приводить к кэшированию и другим, подобным действиям,
которые не желательны для реализации в базе данных требований
ACID. Перезапись также нарушает требования безопасности для
границ секторов. Все файлы журналов транзакций и баз данных
SQL Server не должны подвергаться компрессии.
Компрессия может привести к тому, что производительность
I/O станет узким местом. Служба поддержки Microsoft SQL Server
регистрировала возникновение серьезных проблем с I/O, о
которых сообщали клиенты, пытавшиеся использовать компрессию.
В одном из таких случаев, синхронизация контрольной точки при
сбросе на всего нескольких тысяч буферов возросла от
нескольких секунд до минут. Объём работы, требуемый для
обслуживания компрессии не только повышает нагрузку на
систему, но и увеличивает время кратких блокировок,
накладываемых до завершения I/O, что негативно сказывается на
весь SQL Server.
Microsoft SQL Server 2000 не рассчитан на то, что
находящиеся в режиме только чтения базы данных будут
компрессованными. Поскольку оптимизатор SQL Server 2000 при
формировании планов исполнения запросов ничего не знает о
компрессии файлов, компрессованные файлы могут спровоцировать
увеличение времени исполнения запроса, относительно
ожидаемого. Например, если согласно плану исполнения ожидается
чтение только одной страницы, на самом деле, каждое чтение
потребует извлечения из копрессованного файла отдельных его
кусков для распаковки. Если бы оптимизатор знал о компрессии
файла, он мог бы изменить план, чтобы увеличить долю
упреждающего чтения или пересмотрел бы планируемые операции
выборки данных так, что бы компрессия выполнялась бы меньшее
число раз. Важно: База данных tempdb никогда не должна
подвергаться компрессии, потому что даже если пользовательская
база данных используется в режиме только чтения, объекты для
поддержки запроса могут создаваться в tempdb. В следующих
версиях Microsoft SQL Server, для находящихся в режиме только
для чтения баз, будет введена поддержка компрессии файлов.
Windows позволяет шифровать файлы. SQL Server 2000
поддерживает криптование файлов баз данных и их журналов.
Операционная система занимается только шифрацией и дешифрацией
данных, и не выполняет перезаписи самих блоков данных, либо
операций изменения на границах
секторов. Предупреждение: Убедитесь, что Вы
используете сильную стратегию резервирования для каждого
экземпляра SQL Server, т.к. известно, что криптование может
ограничить возможности восстановления после отказов.
Служба поддержки Microsoft SQL Server сталкивалась в своей
работе с такими аппаратными средствами, которые не были хорошо
приспособлены к листанию и необходимым действиям с файлом
подкачки, например, упорядочивание записи. SQL Server
старается минимизировать листание, сокращая по возможности его
объём. Однако, оно всё ещё может проявляться для связанной с
SQL Server памяти процесса, который сбрасывает страницы.
Подобно механизмам режимов ожидания и пониженного
энергопотребления, листание задействует другие дисковые
устройства; и эти устройства, хотя они и не используются
непосредственно в SQL Server, для обеспечения гарантии
целостности данных должны также быть с точки зрения I/O
совместимы с Microsoft SQL Server. Во время листания,
становится труднее обеспечить целостность находящихся в
оперативной памяти данных. Следующие версии SQL Server могут
комбинировать методы принудительных кратких блокировок с
отслеживанием контрольных сумм в оперативной памяти, что
обеспечивает лучшую защиту от вызванных листанием проблем.
Однако, постоянная проверка контрольных сумм страниц
существенно повысит нагрузку на SQL Server. Важно: Для SQL
Server существует рекомендация Microsoft о том, что бы файл
подкачки размещался на устройстве, которое соответствует
требованиям Microsoft к I/O для SQL Server.
Для облегчения обнаружения нежелательных изменений страниц
данных в оперативной памяти, для SQL Server вводиться флаг
трассировки -T815, которые расширяет возможности
принудительных кратких блокировок. Когда для внесения
изменений на страницу накладывается краткая блокировка,
VirtualProtect страницы устанавливается в PAGE_READWRITE. В
остальное время уровень её защиты будет - PAGE_READONLY. Это
помогает перехватывать такие операции в памяти, как наложенная
запись (scribblers). Начиная с версии Microsoft SQL Server
2000 v. 8.00.0922, появилась возможность динамического
переключения флага трассировки -T815, с использованием
инструкций Transact-SQL: DBCC TRACEON и DBCC
TRACEOFF. Важно: Принудительные краткие блокировки
допустимы только для тех систем, которые не используют AWE
(Address Windowing Extensions) режимы.
Некоторые аппаратные средства резервирования от третьих
фирм предоставляют возможность создания резервных копий
открытых каким - либо ПО файлов, путём их отражения на
аппаратном уровне. Поскольку SQL Server монопольно открывает
все свои файлы баз данных и журналов, такое отражение возможно
только на уровне промежуточных драйверов или на аппаратном
уровне. Типичной проблемой подобных решений является то,
что они не поддерживают порядок меток времени для подобных
снимков файлов. Данные копируются в то время, когда SQL Server
всё ещё продолжает работу, а это может нарушить порядок записи
и семантику меток времени, и привести к невозможности
восстановления файлов баз данных. Некоторые производители
таких аппаратных средств реализуют в своих системах
возможности создания правильных снимков, для чего используется
документированная объектная модель SQL Server Virtual Device
Interface (VDI). Это единственный безопасный способ
фиксировать I/O с соблюдением меток времени для всех
используемых файлов баз данных.
Повторяющееся чтение поддерживается в Microsoft SQL Server
2000 только для операций сортировки. В следующих версиях SQL
Server может появиться повторяющееся чтение и для других
операций I/O. Служба поддержка Microsoft SQL Server
сталкивалась с проблемами, связанными с повторяющимся чтением.
В некоторых системах фиксировалось чтение не корректных
данных. Логика сортировки в SQL Server может порождать чтение
тех же данных (повторяющееся чтение), и при последнем чтении
данные считываются правильными. Поскольку данные должны
возвращаться правильными и при первом чтении, это указывает на
проблемы с хранилищем. Предупреждение: Если ваша
система не показывает признаки успешного повторяющегося
чтения, это нужно рассмотреть, как серьёзный повод для
беспокойства.
Когда происходят сбои операций I/O, считается общепринятым
чаще выполнять проверку согласованности базы данных. Это
помогает получить больше подробностей о степени серьёзности
проблем и затрагиваемых ими участков
данных. Предупреждение: Не стоит злоупотреблять DBCC
REPAIR, для исправления проблем данных. Любые их нарушения, и
особенно постоянные, повторяющиеся искажения, являются
симптомами более глубоких проблем, и часто связанных с
используемыми долговременными носителями.
SQLIOStress.exe моделирует разные схемы поведения I/O в SQL
Server 2000, что позволяет проверить безопасность I/O на самом
простом уровне. Утилита SQLIOStress может быть загружена с
сайта Microsoft. Ниже, представлена ссылка на статью с её
описанием.
Важно: Загружаемый дистрибутив содержит подробное
описание этой утилиты.
Правильные настройка и обслуживание подсистемы I/O являются
критически - важным фактором успешного развертывания SQL
Server. Понимание того, как SQL Server исполняет операции I/O
с файлами журналов транзакций и баз данных, поможет Вам лучше
оптимизировать подсистему ввода - вывода. Выбирайте только
такие дисковые подсистемы, которые в полной мере поддерживают
протокол WAL, позволяя этим SQL Server обеспечивать требования
ACID.